Pwn 栈溢出
栈溢出
前置知识需求
- C、Python
- x86-64、x86 汇编
- gdb、objdump 等工具
- linux
栈
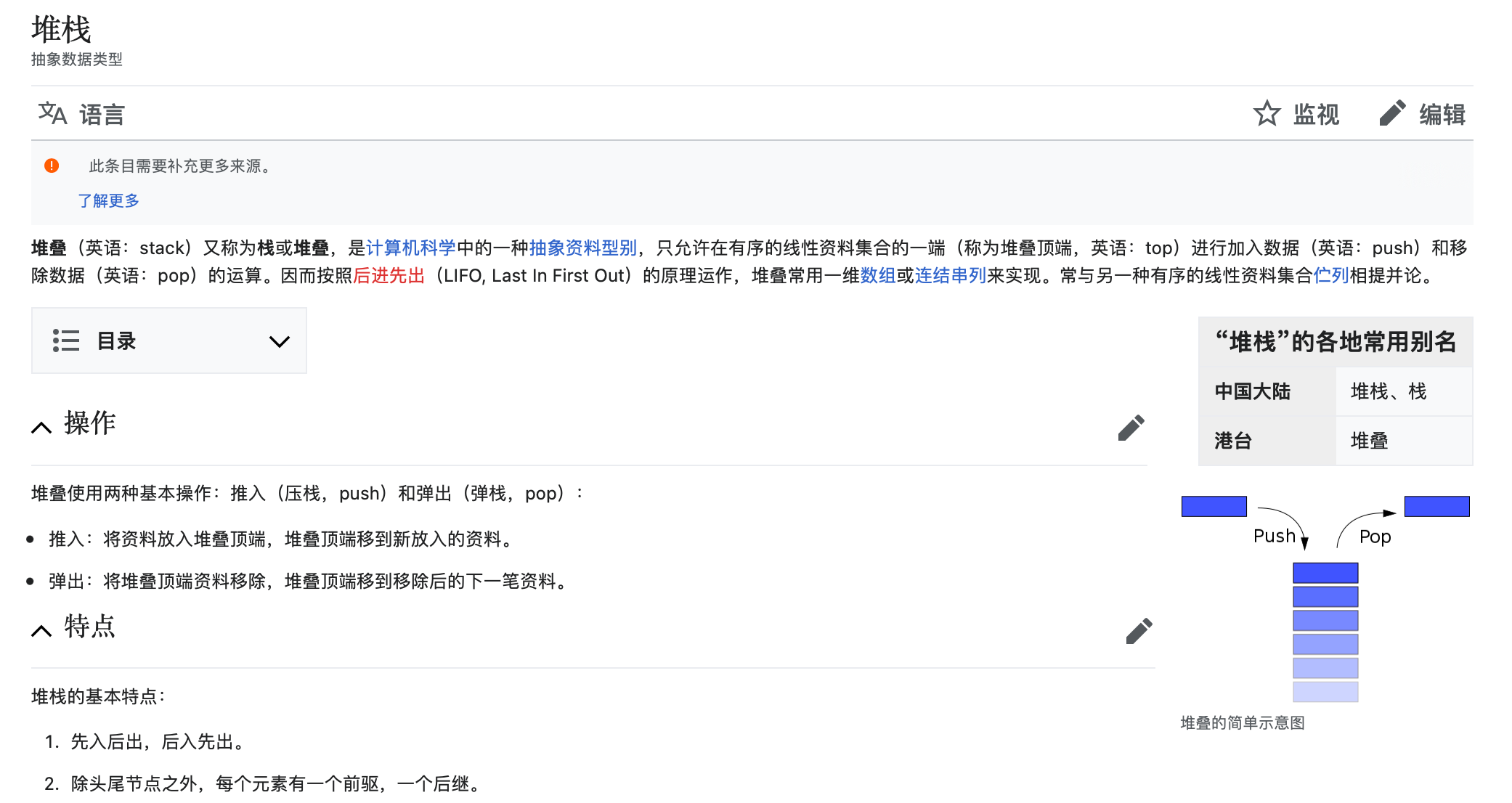
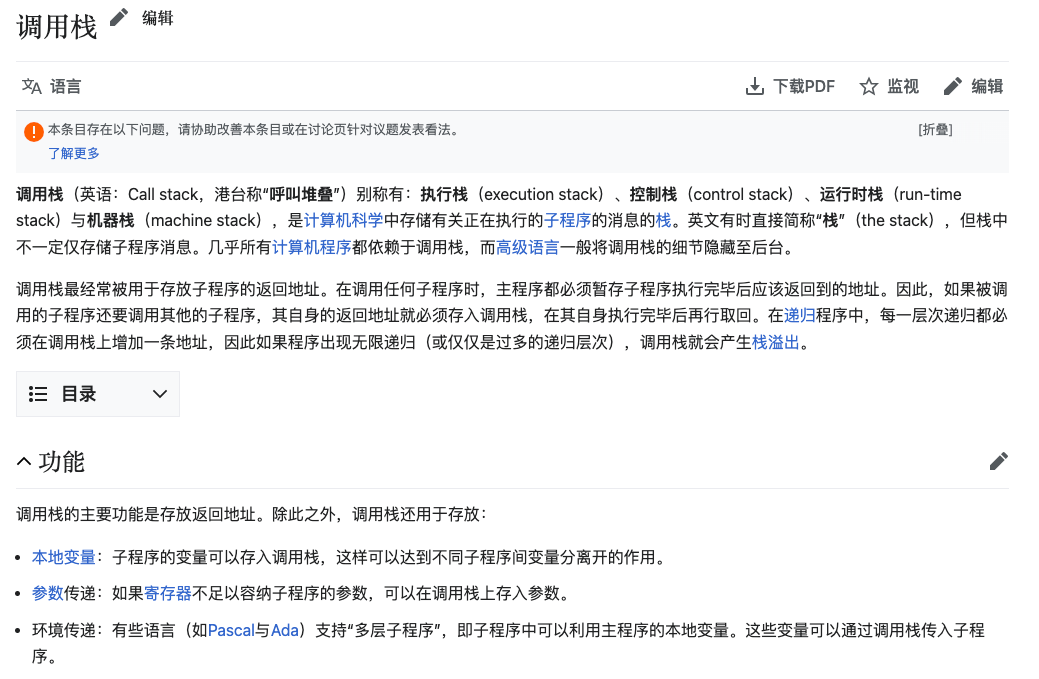
函数调用栈
注意: 以下内容仅涉及 x86 架构CPU,暂不考虑 ARM、MIPS 等架构
一个简单的例子:
1 | // demo.c |
gcc参数说明
-m32用于指明生成 32bit 程序-no-pie用于指明禁用生成位置无关(PIE)文件-fno-pie类似于-no-pie,但这个是作为编译选项来指定的,而-no-pie是作为链接器选项来指定的,这两者的区别可以看这个回答
接下来通过 GDB 进行调试分析:
这里的 GDB 安装了 pwndbg 插件
32bit
- 现在 32bit 的机器很少了,CTF比赛中基本上全是 64bit 的程序
- 重点放在 64bit,不过 32bit 的还是需要学习
接下来是 32bit 的情况:
1 | // gdb call_stack_32 |
当程序执行至 ► 0x8049180 <func+10> mov edx, dword ptr [ebp + 8] 时,此时的栈:
1 | pwndbg> stack 0x10 |
- 32bit 情况下函数参数在函数返回地址的上方 (所有参数都在栈上)
- 内存地址不能大于 0x00007FFFFFFFFFFF,6 个字节长度,否则会抛出异常。
64bit
1 | // gdb call_stack |
进入 func 函数时,此时的寄存器值:
1 | RAX 0x401152 (main) ◂— 0xe5894855fa1e0ff3 |
当执行到 0x401150 <func+74> pop rbp 时,此时的栈:
1 | 00:0000│ rbp rsp 0x7fffffffe320 —▸ 0x7fffffffe340 ◂— 0x0 |
- 64bit 环境下,前六个参数通过寄存器传递 (依次是 rdi, rsi, rdx, rcx, r8, r9),其余的参数再通过栈传递
- 函数返回值通过 rax 寄存器传递
64位的常用寄存器:

📌Q1: endbr64 指令干啥用的

- 来自 csdn 的回答
Intel CET的作用及endbr64指令:
Intel CET提供了影子栈及间接跳转指令追踪功能,保护控制流完整性(wiki: here)。
Intel CET相关的指令如endbr64是后向(backward)兼容的。
在Intel CET中,间接跳转的处理逻辑中被插入一段过程:将CPU状态从DLE切换成WAIT_FOR_ENDBRANCH。
在间接跳转之后查看下一条指令是不是endbr64。如果指令是endbr64指令,那么该指令会将CPU状态从WAIT_FOR_ENDBRANCH恢复成DLE。另一方面,如果下一条指令不是endbr64,说明程序可能被控制流劫持了,CPU就报错(#CP)。因为按照正确的逻辑,间接跳转后应该需要有一条对应的endbr64指令来回应间接跳转,如果不是endbr64指令,那么程序控制流可能被劫持并前往其它地址(其它任意地址上是以非endbr64开始的汇编代码)(涉及编译器兼容CPU新特性)。
📌Q2: 为什么反编译的代码里面没有 sub rsp, xxx
sub rsp, xxx来自 stackoverflow 的回答
The System V ABI for x86-64 specifies ared zoneof 128 bytes below%rsp. These 128 bytes belong to the function as long as it doesn’t call any other function (it is a leaf function).
Signal handlers (and functions called by a debugger) need to respect the red zone, since they are effectively involuntary function calls.
All of the local variables of yourtest_function, which is a leaf function, fit into the red zone, thus no adjustment of%rspis needed. (Also, the function has no visible side-effects and would be optimized out on any reasonable optimization setting).
You can compile with-mno-red-zoneto stop the compiler from using space below the stack pointer. Kernel code has to do this because hardware interrupts don’t implement a red-zone.《CTF权威指南PWN篇》第10章 P185 的解释
这是一项编译优化,rsp 以下 128 字节的区域被称为 red zone,是一块保留内存,不会被信号或中断所修改,函数可以在不调整栈指针的情况下用这块内存保存临时数据。
📙扩展资料
栈溢出原理
转自 ctf-wiki:
- 栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程
- 触发栈溢出的前提
- 程序须往栈上写数据
- 写入的数据长度没有得到良好的控制
可利用函数
想要写数据,就要先寻找能够读取用户输入的函数:
1 | // linux系统调用 - read |
实例
接下来通过一个简单的例子来介绍栈溢出:
1 | // overflow.c |
📌gcc 编译参数里的 -fno-stack-protector 是用来干什么的?
-fno-stack-protector 是用来干什么的? 现在的GCC默认会启用栈保护机制,也就是Stack Canaries, -fno-stack-protector 是用来关闭此保护机制的
思路
- 程序中有一个大小为
0x18的buf,但是可以读取0x20个字节的数据,存在栈溢出漏洞,可以覆盖掉紧邻buf的target变量 - 共输入
0x20个字节的数据,前0x18个字节填充buf,后0x8个字节输入0x1234的字节流,覆盖掉target值即可成功进入 Bingo
我们可以用 python 生成所需要输入的数据:
1 | ❯ python3 -c "from struct import pack; print((b'A'*0x18 + pack('<Q', 0x1234)).decode(), end='')" | ./overflow |
GDB调试看一下 read 后的栈是什么状态:
1 | gdb ./overflow |
断点位置
这里根据需要实际情况下断点,断点下在 call read@plt 之后,用来查看 read 之后的栈状态
- 环境不同可能导致编译出来的程序不一致
- 可以先
disass vuln查看一下
python3-struct的使用:
1 | ───[ DISASM ]─── |
小结
栈溢出是一个特定的缓冲区溢出,通常情况下有这样的缓冲区溢出需求:
- 栈溢出:覆盖特定的局部变量值(如上面的实例)
- 栈溢出:覆盖返回地址(构造ROP等, 下一节内容)
- 数据段溢出:覆盖特定的bss、data段的值
- 堆溢出:覆盖堆中的malloc_chunk的特定值(堆利用章节内容)